因为Few-Shot Learning问题要读取数据组成task,因此如何读取数据组成一个task是一个问题。之前看到好几个Pytorch版本的代码,虽然也实现了读取数据组成task,但是逻辑较为复杂且复杂度较高。最近看到了这个代码,感觉实现的方法特别高级,定制性也很强,但是需要比较深入的理解Pytorch DataLoader的原理。所以便有了这篇文章。
Pytorch读取数据流程
Pytorch读取数据虽然特别灵活,但是还是具有特定的流程的,它的操作顺序为:
- 创建一个 Dataset 对象,该对象如果现有的
Dataset不能够满足需求,我们也可以自定义Dataset,通过继承torch.utils.data.Dataset。在继承的时候,需要override三个方法。__init__: 用来初始化数据集__getitem__:给定索引值,返回该索引值对应的数据;它是python built-in方法,其主要作用是能让该类可以像list一样通过索引值对数据进行访问__len__:用于len(Dataset)时能够返回大小
- 创建一个 DataLoader 对象
- 不停的 循环 这个 DataLoader 对象
对我们来说,本篇文章的侧重点在于介绍 DataLoader,因此对于自定义 Dataset,这里不作详细的说明。
DataLoader参数
先介绍一下DataLoader(object)的参数:
- dataset(Dataset): 传入的数据集
- batch_size(int, optional): 每个batch有多少个样本
- shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序
- sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
- batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再指定了(互斥——Mutually exclusive)
- num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
- collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数;通俗来说就是将一个batch的数据进行合并操作。默认的
collate_fn是将img和label分别合并成imgs和labels,所以如果你的__getitem__方法只是返回img, label,那么你可以使用默认的collate_fn方法,但是如果你每次读取的数据有img, box, label等等,那么你就需要自定义collate_fn来将对应的数据合并成一个batch数据,这样方便后续的训练步骤。 - pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
- drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了…如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
- timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
- worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)
这里,我们需要重点关注sampler和batch_sampler这两个参数。在介绍这两个参数之前,我们需要首先了解一下DataLoader,Sampler和Dataset三者关系。
DataLoader,Sampler和Dataset
在介绍该参数之前,我们首先需要知道DataLoader,Sampler和Dataset三者关系。首先我们看一下DataLoader.next的源代码长什么样,为方便理解我只选取了num_works为0的情况(num_works简单理解就是能够并行化地读取数据)。
1 | class DataLoader(object): |
在阅读上面代码前,我们可以假设我们的数据是一组图像,每一张图像对应一个index,那么如果我们要读取数据就只需要对应的index即可,即上面代码中的indices,而选取index的方式有多种,有按顺序的,也有乱序的,所以这个工作需要Sampler完成,现在你不需要具体的细节,后面会介绍,你只需要知道DataLoader和Sampler在这里产生关系。
那么Dataset和DataLoader在什么时候产生关系呢?没错就是下面一行。我们已经拿到了indices,那么下一步我们只需要根据index对数据进行读取即可了。
再下面的if语句的作用简单理解就是,如果pin_memory=True,那么Pytorch会采取一系列操作把数据拷贝到GPU,总之就是为了加速。
综上可以知道DataLoader,Sampler和Dataset三者关系如下:
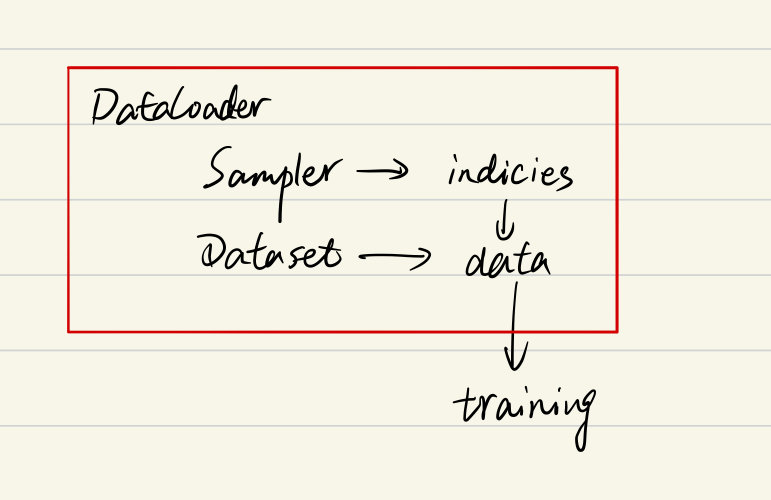
sampler和batch_sampler
通过上面对DataLoader参数的介绍,发现参数里面有两种sampler:sampler和batch_sampler,都默认为None。前者的作用是生成一系列的index,而batch_sampler则是将sampler生成的indices打包分组,得到一个又一个batch的index。例如下面示例中,BatchSampler将SequentialSampler(Sampler的一种)生成的index按照指定的batch size分组。
1 | from torch.utils.data import SequentialSampler, BatchSampler |
从这个例子中可以看出,当BatchSampler中的数据取完了,再使用iter(a)得到新的迭代器对象即可,不需要再次实例化类。
Pytorch中已经实现的Sampler有如下几种(均在torch.utils.data下):
SequentialSampler(若shuffle=False,则若未指定sampler,默认使用)RandomSampler(若shuffle=True,则若未指定sampler,默认使用)WeightedSamplerSubsetRandomSampler
Pytorch中已经实现的 batch_sampler为BatchSampler(在torch.utils.data下,默认使用)
需要注意的是DataLoader的部分初始化参数之间存在互斥关系,这个你可以通过阅读源码更深地理解,这里只做总结:
- 如果你自定义了
batch_sampler,那么这些参数都必须使用默认值:batch_size,shuffle,sampler,drop_last - 如果你自定义了
sampler,那么shuffle需要设置为False - 如果
sampler和batch_sampler都为None,那么batch_sampler使用Pytorch已经实现好的BatchSampler,而sampler分两种情况:- 若
shuffle=True,则sampler=RandomSampler(dataset) - 若
shuffle=False,则sampler=SequentialSampler(dataset)
- 若
源码解析
首先,大概扫一下DataLoader的代码:
1 | class DataLoader(object): |
这里我们主要看__init__()和__iter__():
(1)数据的shuffle和batch处理
- RandomSampler(dataset)
- SequentialSampler(dataset)
- BatchSampler(sampler, batch_size, drop_last)
(2)因为DataLoader只有__iter__()而没有实现__next__()
所以DataLoader是一个iterable而不是iterator。这个iterator的实现在_DataLoaderIter中。
RandomSampler(dataset)、 SequentialSampler(dataset)
这两个类的实现是在dataloader.py的同级目录下的torch/utils/data/sampler.py
sampler.py中实现了一个父类Sampler,以及SequentialSampler,RandomSampler和BatchSampler等五个继承Sampler的子类
这里面的Sampler的实现是用C/C++实现的,这里的细节暂且不表。
我们这里需要知道的是:对每个采样器,都需要提供__iter__方法,这个方法用以表示数据遍历的方式和__len__方法,用以返回数据的长度。
1 | import torch |
输出结果为:
1 | [3, 7, 5, 8, 9, 0, 2, 4, 1, 6] |
可以看出RandomSampler等方法返回的就是DataSet中的索引位置(indices),其中,在子类中的__iter__方法中,需要返回的是iter(xxx)(即iterator)的形式:
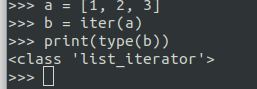
1 | #### 以下两个代码是等价的 |
此外,torch.randperm()的用法如下:
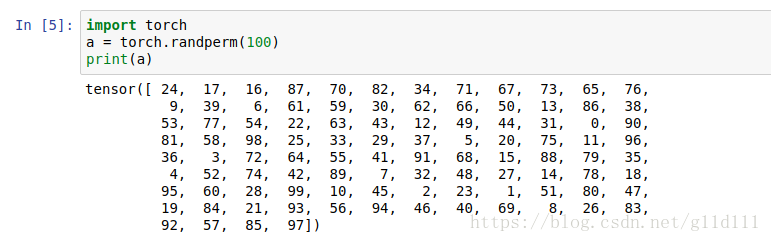
最后,我们再理解一下这些类中间的__iter__函数,该函数的返回值为迭代器对象,可以使用for循环或者next()函数依次访问该迭代器对象中的每一个元素。但是这些类是可迭代类并不是迭代器类,所以上例中的实例对象a只能使用for循环访问__iter__函数返回的迭代器对象,而不能直接使用next()函数,需要使用iter()函数得到__iter__函数返回的迭代器对象。如下所示,可以看到iter(a)后得到的结果为range_iterator,也就是__iter__函数返回的迭代器对象。
1 | a |
BatchSampler(Sampler)
BatchSampler是wrap一个sampler,并生成mini-batch的索引(indices)的方式。代码如下所示:
1 | class BatchSampler(Sampler): |
这里主要看__iter__方法,可以看到,代码的思路很清楚明白的展示了batch indices的是如何取出的。要想理解该方法,最重要的是对于yield关键字的理解。之前我已经有一篇文章解释过yield关键字了。这里只说结论:yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始;同时包含yield的函数为生成器(生成器是迭代器对象),当直接调用该函数的时候,会返回一个生成器。而生成器是迭代器对象,正好对应于前面所述的Sample对象的__iter__(self)函数,返回值需要是迭代器对象。
对于BatchSampler类而言,只含有__iter__含义,但是不含有__next__函数,所以它是一个可迭代类但是不是一个迭代器类。因此只能使用for循环,不能使用next()函数。若想使用next()函数,需要使用iter()函数作用于BatchSampler类的实例,这样就可以得到__iter__函数的返回值即迭代器对象。其实对于含有__iter__的类,使用for循环遍历其数据的时候,内部是内置了__iter__函数了。
总结
假设某个数据集有100个样本,batch size=4时,以SequentialSampler和BatchSampler为例,Pytorch读取数据的时候,主要过程是这样的:
SequentialSampler类中的__iter__方法返回iter(range(100))迭代器对象,对其进行遍历时,会依次得到range(100)中的每一个值,也就是100个样本的下标索引。BatchSampler类中__iter__使用for循环访问SequentialSampler类中的__iter__方法返回的迭代器对象,也就是iter(range(100))。当达到batch size大小的时候,就使用yield方法返回。而含有yield方法为生成器也是一个迭代器对象,因此BatchSampler类中__iter__方法返回的也是一个迭代器对象,对其进行遍历时,会依次得到batch size大小的样本的下标索引。DataLoaderIter类会依次遍历类中的BatchSampler类中__iter__方法返回的迭代器对象,得到每个batch的数据下标索引。
自定义Sampler和BatchSampler
仔细查看源代码其实可以发现,所有采样器其实都继承自同一个父类,即Sampler,其代码定义如下:
1 | class Sampler(object): |
所以你要做的就是定义好__iter__(self)函数,不过要注意的是该函数的返回值需要是迭代器对象。例如SequentialSampler返回的是iter(range(len(self.data_source)))。
另外BatchSampler与其他Sampler的主要区别是它需要将Sampler作为参数,打包Sampler中__iter__方法返回的迭代器对象的迭代值,进而每次迭代返回以batch size为大小的index列表。也就是说在后面的读取数据过程中使用的都是batch sampler。
参考
一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系
PyTorch学习笔记(6)——DataLoader源代码剖析
彻底理解Python中的yield

